
Innholdsfortegnelse
Hva er reliabilitet?
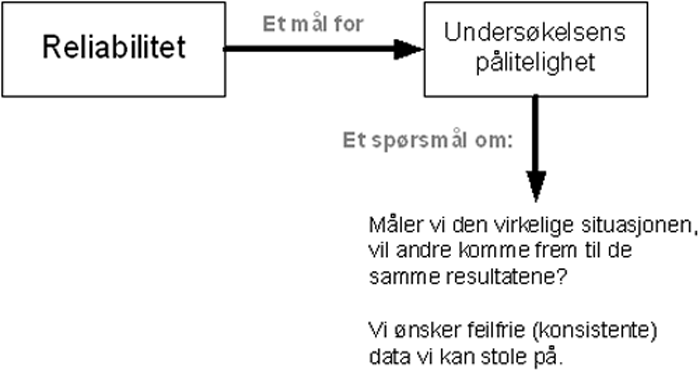
Reliabilitet betyr pålitelighet, og er en angivelse av om undersøkelsen viser den virkelige situasjonen og i hvilken grad resultatene kan etterprøves.
Reliabilitet måles på en skala som går fra høy til lav reliabilitet.
Høy rentabilitet vil si at alle uavhengige målinger andre gjør av samme fenomen skal alltid resultere i at de kommer frem til et tilnærmet identiske resultat eller konklusjon. Det vil si at hvis en annen forsker gjennomfører en identisk undersøkelse, basert på de samme premissene og metodene, skal de alltid komme fram til samme resultat. Skjer ikke dette er resultatenes reliabilitet lav. Vi kan dermed si at reliabilitet er en angivelse av målingenes konsistens og stabilitet. også kalt målingstabilitet.
Reliabiliteten forteller som sagt i hvilken grad en studie kan etterprøves, I denne sammenheng skiller vi mellom indre- og ytre reliabilitet
Indre reliabilitet
Intern konsistens, også kalt indre konsistens, viser evnen til å produsere like resultater ved å benytte forskjellige utvalg til å måle et fenomen under den samme tidsperiode.
Den indre reliabilitet forteller i hvilken grad andre forskere kan bruke begrepsapparatet i et studie på samme måte i sine egne studier og analyser. Er begrepsapparatet ikke direkte overførbart oppstår reliabilitet problemer.
Indre konsistens er med andre ord et mål på samsvar mellom ulike testledd som til sammen skal gjenspeile individuell variasjon om et gitt fenomen.
Ytre reliabilitet
Den ytre reliabiliteten angir i hvilken grad ulike forskere vil oppdage samme fenomen, generere samme begreper i den aktuelle og liknende situasjoner

")

")



")

