
Hva er skjevhet og normalfordeling?
Når utvalget skal beskrives, vil det alltid være interessant å vite om det finnes skjevheter i utvalget eller om utvalget er normalfordelt. Spesielt viktig er dette hvis vi ønsker å generalisere resultatene til å gjelde hele populasjonen.
For å kunne utføre statistiske beregninger som baserer seg på en normalfordeling, må det ikke være store skjevheter i stikkprøven for at resultatet skal være pålitelig og gyldig. Vis derfor hvordan stikkprøven er sammensatt, slik at leserne av analysen kan danne seg et bilde av hvilke skjevheter som eventuelt finnes i stikkprøven.
For å kunne bruke en normalfordeling må utvalget helst være symetrisk fordelt. Det vil si at avstanden mellom ![]() og
og ![]() skal være lik avstanden mellom
skal være lik avstanden mellom ![]() og
og ![]() .
.
Sentralgrenseteoremet – normalfordelt
Er utvalget symetrisk fordelt, sier vi at utvalget er normaltfordelt. Normalfordelings begrepet bygger på en teori som kalles sentralgrenseteoremet. En teori som står sentralt i alle undersøkelser som tilstreber statistisk inferens. Det vil si i undersøkelser hvor vi ønsker å kunne generalisere resultatene.
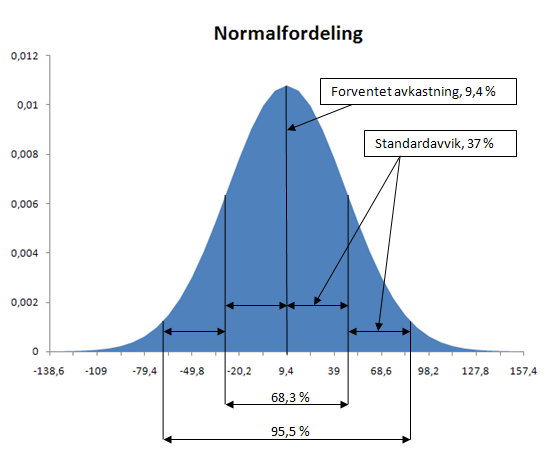
Egenskaper ved normalfordelingen:
Symmetri: Normalfordelingen er symmetrisk rundt gjennomsnittet (mean). Dette betyr at høyre og venstre side av fordelingen er speilbilder av hverandre.
Gjentakende mønster: Fordelingen er klokkeformet, med de fleste verdiene samlet rundt gjennomsnittet. Verdier langt fra gjennomsnittet er sjeldne.
Gjennomsnitt, median og modus: I en perfekt normalfordeling er gjennomsnittet (mean), medianen, og modus (den hyppigste verdien) alle like og ligger i midten av fordelingen.
Standardavvik: Områdene under kurven representerer sannsynligheter. For en normalfordeling ligger:
- Cirka 68 % av dataene innenfor én standardavvik fra gjennomsnittet.
- Cirka 95 % av dataene innenfor to standardavvik fra gjennomsnittet.
- Cirka 99,7 % av dataene innenfor tre standardavvik fra gjennomsnittet.
Asymptotisk: Halen på kurven nærmer seg, men treffer aldri, x-aksen. Dette betyr at det er en liten sannsynlighet for svært ekstreme verdier, men de er uendelig sjeldne.
Andre viktige karakteristika ved en normalfordeling er:

")
")


