
Lesetid (240 ord/min): 7 minutter
Når dataene er samlet inn, kan man begynne å analysere dataene. Eller sagt på en annen måte; kategoriserer de innsamlede dataene med sikte på å beskrive og forstå hva vi har funnet. Hva karakteriserer dataene? Finnes det mønstre og/eller relasjoner? Kan sammenhengen mellom variablene skyldes årsaksforhold?
Hvor langt en skal gå i dataanalysen er avhengig av:
- formålet med undersøkelsen
- undersøkelsens rammebetingelser (Tid, penger og kompetanse).
- utvalget og variablenes egenskaper og målenivå.
En generell modell for hvordan dataanalysen bør gjennomføres er denne:
- Definer analyseformålet (Hvordan analysen skal løse problemstillingen)
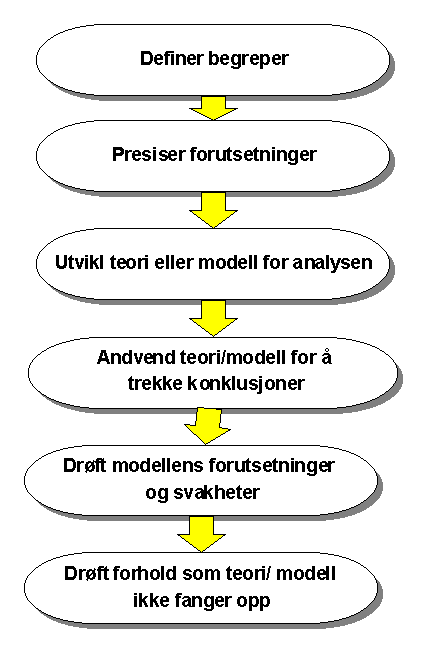
- Definer nøkkelbegreper og presiser forutsetninger
- Velg/utvikl en teorieller modell for analysen
- Beskriv de innsamlede rådataene
- Vurder og korriger rådataene i forhold til analyseformålet
- Grupper rådataene i forhold til analyseformålet
- Foreta tekniske analyse av dataene. Beregn relevante forholdstall, tabeller o.l.
- Anvend teori/modell for å vurdere analyseresultatet og trekke konklusjoner
- Drøft modellens forutsetninger og svakheter
- Drøft forhold som teori/modell ikke fanger opp
- Utarbeid en presentasjon av analyseresultatene
Hvilke feilkilder dataene vil være beheftiget med, vil være avhengig av om man har benyttet seg av en kvalitativ eller kvantitativ datainnsamlingsmetode. De viktigste feilkildene og forholdene som må tas med i betraktning når feilkildene skal vurderes, er beskrevet senere.
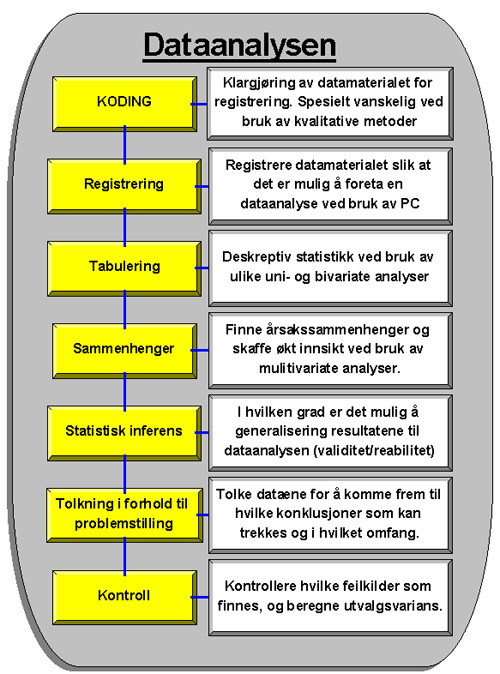
Med utgangspunkt i modellen under, kan de viktigste fasene i analysearbeidet sammenfattes slik:
Innholdsfortegnelse
Koding og registrering
De innsamlede dataene må klargjøres slik at det er mulig å registrere de for videre analyser.
For at det skal være mulig å analysere dataene ved hjelp av et dataprogram, må svarene til respondentene kodes. Dette fordi det er vanskelig å få en database til å sortere dataene etter ord og uttrykk.
Statistikk-programmer og regneark liker best tallkoder.For å få et pålitelig resultat er det viktig at man ikke foretar kodingsfeil. Dvs. koder- eller kategoriserer de innsamlede variablene og verdiene feil.
Siden vi hovedsakelig benytter oss av lukkede spørsmål i kvantitative undersøkelser er det relativt lett å unngå kodefeil, da svaralternativene er gitt på forhånd. Det gjør det også mulig for oss å kode spørreskjemaet eller telleaperatet på forhånd, før undersøkelsen tar til. Når de innsamlede dataene så foreligger er det bare å punche dem rett inn i databasen som skal danne grunnlaget for dataanalysen.
Benytter vi oss av en kvalitativ datainnsamlingsmetode er det ikke fullt så enkelt å unngå kodefeil. Dette fordi vi stiller åpne spørsmål og mottar kvalitative data. Svaralternativene er ikke gitt på forhånd og variablene repondenten benytter i svaret sitt er som regel ikke endimensjonale.De er som regle flerdimensjonale. Dette gjør at vi må foreta en subjektiv tolkning av svaret/variablene når vi skal kategorisere (kode) respondentens svar. Det er derfor langt vanskeligere å kode svarene fra en kvalitativ undersøkelse, og faren for kodefeil er overhengende.
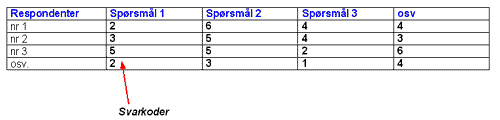
Å kode spørreskjemaet betyr at vi gir hvert spørsmål i spørre-skjemaet et unikt numerisk nummer. Spørsmål nr. 1 gir vanligvis koden 1, spørsmål nr. 2 får koden 2, spørsmål nr 3 får koden 3 osv.Svaralternativene vi gir respondenten går ut på å plassere svaret på en skala, foreta en prioritering, velge ut de viktigste attributtene o.s.v. Dette gjør det lett å registrere svarene, da det er lett å kategorisere svarene.
Svar-alternativene i de ulike spørsmålene koder vi på samme måte som spørsmålene. Svaralternativ 1 gis koden 1, svaralternativ 2 gis koden 2 osv. Dette gjør det mulig å registrere både de ulike spørsmålene og svaralternativene i en database, hvor det er mulig å analysere dataene statistisk. Måten vi gjør det på er å lage en to – dimensjonal matrise. Kolonnene representerer de ulike spørsmålene i undersøkelsen, mens radene angir svarene til de ulike respondentene.
Tabulering
Når dataene er registrert, er det vanlig å starte analysearbeidet med deskreptiv statistikk. Det vil si å beskrive de enkelte variablene i det innsamlede datamaterialet (fordelingsanalyse, frekvensfordeling, krysstabulering osv.).
Sammenhenger
Som regel er man ikke fornøyd å få en beskrivelse av undersøkelsesfenomenet. Man ønsker som regel å finne årsakssammenhenger, bakenforliggende forklaringer, mellomliggende variabler, forklaringer som omfatter flere enn to uavhengige/avhengige variabler. Forklaringene og sammenhengene finner vi ved å benytte oss av ulike multivariate analyser.
Statistisk inferens
Statistisk inferens betyr å generalisere fra en stikkprøve eller et utvalg til en populasjon. Etter at vi har beskrevet variablene i utvalget, kan vi begynne å teste resultatenes gyldighet og pålitelighet (validitet og reabilitet), samt foreta de statistiske testene og analysene som vi finner hensiktsmessig for å kunne komme frem til konklusjoner som gir svar på problemstillingen vår
Tolkning og kontroll
Nest siste faste i analysearbeidet er å tolke resultatene som vi har kommet frem til gjennom tester og analyser av det innsamlede datamateriellet.
Kontroll/feilkilder
I enhver markedsundersøkelse, uansett metode og analyseverktøy, vil det alltid finnes usikkerheter og potensielle feilkilder som kan gjøre at vi trekker feilaktige konklusjoner. For at det skal være mulig å feste noe lit til konklusjonene som undersøkelsen har kommet frem til er det derfor påkrevd at man prøver å avdekke alle uklarheter og potensielle feilkilder.
Overstående modell viser på en enkel måte de viktigste fasene i et tradisjonelt markedsforskningsprosjekt, men sier lite om hvordan man skal angripe analysen av de innsamlede forskningsdataene. Modellen under er i så måte noe bedre, da den tar for seg prosessen og ikke fasene ved analysen:
- Beskriv de innsamlede rådataene.
- Vurder og korriger rådataene i forhold til analyseformålet.
- Grupper rådataene i forhold til analyseformålet
- Foreta teknisk analyse av forskningsdataene. Beregn relevante forholdtall, tabeller o.l.
- Vurdere analyseresultatene og trekk konklusjoner.
- Utarbeid en presentasjon av analyseresultatene.
Den analytiske vitenskapligemetode
Svakheten ved begge overstående modeller er at de er lite vitenskapelige.
En mer vitenskapelig analysemodell er denne som innen samfunnsøkonomien kalles for “den analytiske vitenskapligemetode“.
Noen viktige forskjeller mellom kvalitative og kvantitative metoder som gjør at dataanalysen ofte blir vesentlig forskjellig kan sammenfattes i følgende matrise:
| Kvalitative metoder | Kvantitative metoder |
|
|
Hvor langt en skal gå i dataanalysen er avhengig av formålet med undersøkelsen. I sin enkleste form går analysen ut på å gi en tallmessig beskrivelse av problemstillingen. Men som regel er siktemålet å komme fram til mer sammensatte forklaringer om undersøkelsesenhetene.
Analysemetodene du ønsker å benytte, bør ideelt sett velges før undersøkelsen starter. Tar man ikke hensyn til hvordan man har tenkt å analysere resultatene når man velger undersøkelsesproblem og operasjonaliserer problemet, kan man risikere å bli sittende med store datamengder som er ubrukelig. De forskjellige analysemetodene krever forskjellige variabler, finnes ikke disse variablene i det innsamlede datamaterialet i en slik form at de lar seg bruke i analysemetodene, er undersøkelsen nærmest bortkastet. Ellers er hovedprinsippet ved valg av analysemetode: “Velg den enkleste og bare de metodene som du behersker“.
Faktorer som avgjør analysearbeidet
Den viktigste enkeltfaktoren som avgjør analysevalget erproblemstillingen. Dette fordi analysens formål er å løse problemstillingen forskningsprosjektet bygger på. Deretter vil faktorer som tid, penger, kunnskap og ressurser styre analysevalget i stor grad.
Etter at man har tatt hensyn til overstående faktorer, vil de innsamlede dataene i seg selv avgjøre hvilke analyser vi kan gjøre. Når det gjelder det innsamlede datamaterialet vilutvalget og variabelens egenskaper og målenivå vil være de største begrensningen for hva slags analyse som kan foretas.
Utvalget
Om utvalget er normalfordelt eller ikke, har stor betydning for hvilke statistiske metoder som kan brukes. Vi skiller i denne sammenheng mellom parametiske og Ikke – parametiske tester.
Hvilke statisktiske metoder som kan brukes på normalfordelte utvalg og ikke, er vist i tabellene under.
Målinger
| Ikke normalfordelt utvalg | Normalfordelt utvalg | |
| En stikkprøve | Ordningsobservatorene | T – fordelingen |
| To stikkprøver | Mann – Whitney | Welch t-fordeling |
| Parvise sammenligninger | Fortegnstest og Wilcoxons tegnrangtest | T – test |
Andeler og tellinger
| Ikke normalfordelt utvalg | Normalfordelt utvalg | |
| En stikkprøve | Eksakt binomisk | Normaltilnærmelsen |
| To stikkprøver (2×2 tabell) | Normaltilnærmelsen Fichers eksakte metode Kji – kvadrat | |
| r X k tabeller | Kji – kvadrat |
Samvariasjon
- Korrelasjonskoeffesient
- Kovarians
- Regresjon
Har man et normalfordelt utvalg er kan bruke alle statisktiske metoder. Har man et utvalg som ikke er normalfordelt, kan man ikke bruke noen av de metodene som er utarbeidet for normalfordelte utvalg.
Variabelens egenskaper
Grovt sett skiller vi mellom:
- Dikotome variabler
- Diskontinuerlige variabler
- Kontinuerlige variabler
- Avhengige/uavhengige variabler
Variabelens målenivå og målenivåets konsekvens
Når det gjelder variabelens målenivå skiller vi mellom nominal-, ordinal-, intervall- og forholdstall.
- Nominialnivå
- Ordinalnivå
- Intervallnivå
- Rationnivå (forholdstall)
Jo høyere målenivå variabelen er på, desto mer avanserte statistiske teknikker kan man benytte i analysen. F.eks. kan man bare benytte standardavviksom et spredningsmål når variablene er på forholdstallnivå.
Typetallet (den verdipå variabelen som forekommer oftest) kan benyttes på alle nivåer, men er på nominalnivå det eneste målsom kan benyttes på sentraltendens. For å kunne bruke medianensom et mål på sentraltendensen, er det en forutsetning at variabelen ligger på ordinalnivå eller et enda høyere nivå. Variasjonsbredden (antall kategorier av svar) er det eneste spredningsmål som kan benyttes når variabelen er på nominalnivå. Variabelens målenivået avgjør med andre ord hvilke regneoperasjoner som kan utføres i analysen av de innsamlede dataene.



")







