
Forskning går ut på å samle inn, organisere og analysere data for å belyse en problemstilling vi har valgt å studere. Av den grunn er det viktig å vite hva data egentlig er.
Innholdsfortegnelse
Hva er data?
Informasjon vi samler inn gjennom et studie kaller vi for data eller fakta. Data er det laveste nivået i informasjonens kontekstuelle struktur. En mye brukt definisjon av begrepet data er:
“Data er informasjonskomponenter, f.eks. figurer, symboler eller bokstaver, uten selvstendig mening”
Et datum betyr rett oversatt “det som er gitt“, altså en opplysning, en informasjon, en observasjon, en beskrivelse e.l. Definisjonen “data” innbefatter med andre ord ethvert registrerbart fenomen. Av den grunn kan vi betrakte nærmest alt rundt oss som et potensielt datagrunnlag.
Data er verdier en variabel kan måles i
Data er i praksis ikke noe annet enn: “verdier en variabel kan måles i“. Med verdi menes: “De forskjellene som finnes ved en variabel“.
Variabelen “alder” gir verdier av typen 4, 12, 21, 32, hvor tallene er mulige verdier, dvs. aldre som variabelen “alder” kan måles i. Sammenhengen mellom verdier, variabler og enheter kan illustreres slik:
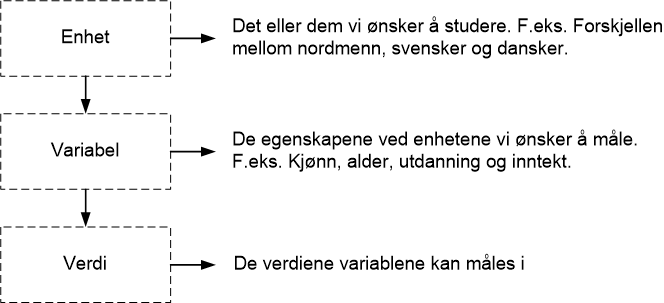
For nærmere informasjon les: “Variabel og verdi“.
Hva brukes data til?
Data er informasjon som brukes til å beskrive, analysere eller ta en beslutning om noe.
Hvordan oppstår data?
Data oppstår ved at vi samler inn, organiserer og analyserer informasjon gjennom observasjoner, målinger, forskning eller analyser. Dataene som organiseres presenteres gjerne i form av grafer, diagrammer eller tabeller.
Datatyper : – Hvilke typer data finnes?
Siden definisjonen av begrepet data er så bred finnes det mange ulike datatyper. Noen vanlige grupperinger er:
- Rådata vs behandle data
- Primær data vs sekundær data
- Kvantitative data vs kvalitative data
- Verbale data vs ikke-verbale data
- Situasjonsdata vs lagrede data
Rådata vs behandlede data
Det mest grunnleggende skillet går mellom:
- Rådata – Rådata er en betegnelse vi bruker på datamateriale slik det foreligger i sin opprinnelige form. Dvs. før vi har begynt å sortere, gruppere og analysere de innsamlede dataene.
- Behandlet data – er det motsatte av rådata. Dette er data som er kodet, organisert, gruppert og analysert.
Rådata er data i utgangspunktet verdiløs informasjon som ikke kan brukes til noe før den er behandlet. Hvis vi f.eks. setter opp følgende tallrekke: 4, 9, 13, 15, 21, 25 og 32. Hva forteller denne tallrekken deg? Egentlig ingenting nyttig, da vi ikke vet hva tallrekken er et uttrykk for.
Får vi vite at dette er alderen flyktningene som kom til Norge igår sier dataene oss langt mer. Vi kan da organisere og gruppere dataene og slå fast at det kom 7 flyktninger igår, 6 av 7 var under 30 år, medianalderen var 15 år, mens gjennomsnittsalderen var 17 år. Forskjellen mellom median- og gjennomsnittsalderen var 2 år. Som vi ser gir dataene oss stadig større mening etter hvert som vi bearbeider og analyserer dem, men på den andre side øker også sjansene for feilkilder som knyttes til hvordan vi behandler og analyserer rådataene. Vi må derfor alltid oppgi hvilke bearbeidelse- og analysemetoder vi har benyttet oss av for at andre skal kunne stole på dataene våre og for at de skal kunne etterprøve dem for å få verifisert våre funn.


")
")







 / Utvalgsenhet")